
文章概要:作者山脚下的蚂蚁简要介绍了临床试验盲法和随机的概念、及临床实施的细节等
开篇声明:1:以下内容非原创,转自微信公众号山脚下的蚂蚁《5 随机化如何在临床试验中应用?》,如有侵权,可联系删除
2. 以下观点,仅代表作者个人观点,请带着质疑的态度去阅读。如有问题,欢迎评论区留言或直接联系作者
随机化如何在临床试验中应用?
前言
好久没更新,也是时候科普一下统计入门的知识了。我都忘记自己是统计师了。不过说来惭愧,水平有限,想讲的内容很多,又不知道从何说起。那就从基本的随机和药物编盲开始吧。如果说得不够深入,或您有任何的不解,抑或是纰漏,欢迎大家私信交流。
盲法、随机和对照是避免偏倚的重要手段。本篇小编从盲法分类入手,然后针对随机从定义、相应的编程(code)、临床实施、盲底等方面进行说明。
正文
盲法分类
开篇之前,有必要先说一下临床试验中的盲态分类,通常有三种状态:开放、单盲、及双盲。(有些人会说还有三盲,但其实我在临床试验中从未遇到,NMPA的《药物临床试验盲法指导原则》也未提及三盲哦)。
指导原则参见https://www.cde.org.cn/main/news/viewInfoCommon/d32fdd9744fab914a3d8c360eac14e3c[1]
开放试验
-
开放试验:受试者的用药信息是开放的,即受试者自己以及研究者均知晓受试者的用药信息或者随机分组。
故开放试验,药物标签是开放的,标签上可以显示药物名称。尽量是开放试验,也不代表申办方团队可以知道受试者的用药信息。即使申办方临床操作团队可能是知晓受试者的用药信息,但是数据库里的随机分组信息可能被FDA/NMPA要求对申办方团队设盲。 指导原则上也建议,尽管是开放试验,随机分配表也应该严格保持盲态。
(如果申办方知道分组情况,就可能开展组间的分析和比较,这就会代来潜在的偏倚。这同NMPA指导原则中的要求一致:开放试验不允许试验过程中进行治疗分组之间的分析和比较。)
单盲试验
-
单盲试验:用药信息仅对受试者设盲,即受试者不知道自己的用药或随机分组,但研究者是知道的。
故药物标签上不可以显示药物名称。那么研究者如何知道受试者的分组呢?不是还有盲底(受试者随机分组列表、或者随机信封等)或者数据库里的随机分组页面吗?这个信息对于研究者可以开放的。同开放试验,同样建议,随机分组依然对申办方保持盲态。
双盲试验
-
双盲试验:顾名思义,就是用药信息对受试者和研究者均保持盲态。即受试者和研究者均不知道受试者用的什么药或者随机分组。
故双盲试验,药物标签上是绝对不能显示药物名称的。对申办方的研究团队(包括临床操作)也需要保持盲态。双盲试验是最严格的盲法,试验启动后,除了非盲的随机统计师,几乎无人知晓受试者的随机分组或者用药信息。
治疗模拟
双盲试验,需要从药物的外观、气味、用药的剂量(药片的数量)、频率等方面需要做到一致,通常需要模拟片来协助。
-
单模拟:模拟一种药物。比如,试验药和安慰剂对照:

-
双模拟:模拟两种药物。比如,试验药和对照药对照,假设分别是药片和胶囊:

随机
在盲法分类概念清晰后,接下来引入随机的概念。
相关指导原则《药物临床试验随机分配指导原则》参见https://www.cde.org.cn/main/news/viewInfoCommon/402c511b46bfa8c472fd6aad6e164557[2]
定义
随机在临床试验方案中通常指的是随机分组,顾名思义,就是采用随机的方式来给受试者分配治疗组别。
操作层面的随机不仅包括受试者的随机分组,还包括药物的随机编号。
药物的随机编号,即采用随机的方式来进行药物编号,要求从药物编号上无法推断具体药物是什么。
方式
随机的方式有很多种,在临床上的应用主要为简单随机化、区组随机化、分层区组随机化、动态随机化等。这里我仅针对临床较为常用的区组随机化及分层区组随机化进行简单说明。
区组随机化
顾名思义,一个区组一个区组的进行随机,一个区组里治疗组和对照组人数均衡;区组长度一般是治疗组别个数的2-3倍。比如方案设计中包括两个治疗组,我们采用区组长度为治疗组的2倍,则每4个人为一个区组,一个区组里试验药和对照药人数均衡(即相等)。这样的话,可以保持试验药组和对照药组随机人数的任何时刻基本均衡。
分层区组随机化
由于临床试验经常将显著影响预后(疗效)的因素设置为分层因素,(为了使相同水平的受试者保持治疗组间人数均衡。 一般来说分层因素不宜过多,通常最多不超过3个。)每个层采用区组随机化,就是分层区组随机化。但如果层数过多,可能会造成组间整体上的不均衡。
假如,某临床试验按照性别(男、女)以及年龄分组(>65, <=65)分层,将40例受试者按照1:1的比例随机到试验组和对照组。层数为2x2=4个分层,采用分层区组随机化,区组长度假设为4,那么极端情况下可能会产生每个层试验组比对照组都多2个受试者,即总体上试验组比对照组多4x2=8个人。
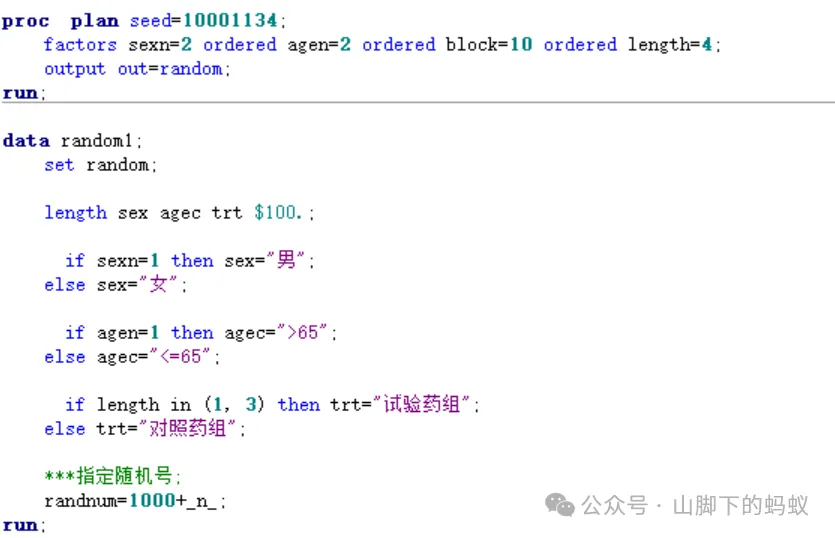
SAS Code
拿上边分层区组随机化部分的案例为例,随机分配表应该如何生成呢?下图程序供参考。
-
为了能够重现,需要指定种子数(也可以选择随机生成种子数,但需要注意种子的唯一性) -
由于无法预测未来入组受试者分层的情况,故扩大样本量,最极端的情况莫过于,40例受试者为同一分层 -
计划每层人数后,设计区组长度,计算区组个数 -
然后指定随机分层因素、随机分组名称和随机号(具体指定取值参考方案上的取值)
临床实施
临床又是如何实施随机化呢?从IVRS 交互语音应答系统 (Interactive Voice Response System)到IWRS 交互网络应答系统(Interactive Web Response System)。IVRS现在已经很少用,基本上都是通过IWRS来实现随机。这个需要相关人员对IWRS进行系统配置、测试然后才可以上线并导入正式的盲底。然后临床相关人员通过触发随机相关EDC/IWRS 相关页面即可以进行筛选成功受试者的随机分组。
还有另一种随机的形式,在早期临床也较为常见,即使用随机信封。
-
对于开放试验,打印一套信封,用于随机(起到分配隐藏的作用)。
为筛选成功准备入组的受试者打开一个信封,来查看其分组,然后取对应的药物给Ta即可。
-
对于双盲试验,可以打印一套信封,用于紧急揭盲。
按照随机表的顺序进行药物编盲(即贴标签),标签上显示药物号(通常=随机号或者至少可以和随机号建立联系,比如随机号后加“-1”)。为筛选成功准备入组的受试者按照方案规定的顺序发放随机号并取对应的药物编号的药物给Ta。这里的随机信封仅用于紧急揭盲。
盲底
盲底,说直白一点就是,受试者随机分组的随机分配表。随机分配表、相关种子数和区组长度在临床试验进行中全程保密。

无论是开放试验还是双盲试验,除非方案明确规定,盲底通常都是在临床试验结束后,DBL后进行释放。
结语
最近有点懈怠了。。。先写这么多吧。。。
大家如果有问题,欢迎私信我~
如果有纰漏,也欢迎批评指正~
https://www.cde.org.cn/main/news/viewInfoCommon/d32fdd9744fab914a3d8c360eac14e3c: https://www.cde.org.cn/main/news/viewInfoCommon/d32fdd9744fab914a3d8c360eac14e3c
[2]https://www.cde.org.cn/main/news/viewInfoCommon/402c511b46bfa8c472fd6aad6e164557:
完结
文章来源:5 随机化如何在临床试验中应用? (qq.com)













0条评论