
文章概要:作者山腳下的螞蟻簡要介紹了臨床試驗盲法和隨機的概念、及臨床實施的細節等
開篇宣告:1:以下內容非原創,轉自微信公眾號山腳下的螞蟻《5 隨機化如何在臨床試驗中應用?》,如有侵權,可聯絡刪除
2. 以下觀點,僅代表作者個人觀點,請帶著質疑的態度去閱讀。如有問題,歡迎評論區留言或直接聯絡作者
隨機化如何在臨床試驗中應用?
前言
好久沒更新,也是時候科普一下統計入門的知識了。我都忘記自己是統計師了。不過說來慚愧,水平有限,想講的內容很多,又不知道從何說起。那就從基本的隨機和藥物編盲開始吧。如果說得不夠深入,或您有任何的不解,抑或是紕漏,歡迎大傢俬信交流。
盲法、隨機和對照是避免偏倚的重要手段。本篇小編從盲法分類入手,然後針對隨機從定義、相應的程式設計(code)、臨床實施、盲底等方面進行說明。
正文
盲法分類
開篇之前,有必要先說一下臨床試驗中的盲態分類,通常有三種狀態:開放、單盲、及雙盲。(有些人會說還有三盲,但其實我在臨床試驗中從未遇到,NMPA的《藥物臨床試驗盲法指導原則》也未提及三盲哦)。
指導原則參見https://www.cde.org.cn/main/news/viewInfoCommon/d32fdd9744fab914a3d8c360eac14e3c[1]
開放試驗
-
開放試驗:受試者的用藥資訊是開放的,即受試者自己以及研究者均知曉受試者的用藥資訊或者隨機分組。
故開放試驗,藥物標籤是開放的,標籤上可以顯示藥物名稱。儘量是開放試驗,也不代表申辦方團隊可以知道受試者的用藥資訊。即使申辦方臨床操作團隊可能是知曉受試者的用藥資訊,但是資料庫裡的隨機分組資訊可能被FDA/NMPA要求對申辦方團隊設盲。 指導原則上也建議,儘管是開放試驗,隨機分配表也應該嚴格保持盲態。
(如果申辦方知道分組情況,就可能開展組間的分析和比較,這就會代來潛在的偏倚。這同NMPA指導原則中的要求一致:開放試驗不允許試驗過程中進行治療分組之間的分析和比較。)
單盲試驗
-
單盲試驗:用藥資訊僅對受試者設盲,即受試者不知道自己的用藥或隨機分組,但研究者是知道的。
故藥物標籤上不可以顯示藥物名稱。那麼研究者如何知道受試者的分組呢?不是還有盲底(受試者隨機分組列表、或者隨機信封等)或者資料庫裡的隨機分組頁面嗎?這個資訊對於研究者可以開放的。同開放試驗,同樣建議,隨機分組依然對申辦方保持盲態。
雙盲試驗
-
雙盲試驗:顧名思義,就是用藥資訊對受試者和研究者均保持盲態。即受試者和研究者均不知道受試者用的什麼藥或者隨機分組。
故雙盲試驗,藥物標籤上是絕對不能顯示藥物名稱的。對申辦方的研究團隊(包括臨床操作)也需要保持盲態。雙盲試驗是最嚴格的盲法,試驗啟動後,除了非盲的隨機統計師,幾乎無人知曉受試者的隨機分組或者用藥資訊。
治療模擬
雙盲試驗,需要從藥物的外觀、氣味、用藥的劑量(藥片的數量)、頻率等方面需要做到一致,通常需要模擬片來協助。
-
單模擬:模擬一種藥物。比如,試驗藥和安慰劑對照:

-
雙模擬:模擬兩種藥物。比如,試驗藥和對照藥對照,假設分別是藥片和膠囊:

隨機
在盲法分類概念清晰後,接下來引入隨機的概念。
相關指導原則《藥物臨床試驗隨機分配指導原則》參見https://www.cde.org.cn/main/news/viewInfoCommon/402c511b46bfa8c472fd6aad6e164557[2]
定義
隨機在臨床試驗方案中通常指的是隨機分組,顧名思義,就是採用隨機的方式來給受試者分配治療組別。
操作層面的隨機不僅包括受試者的隨機分組,還包括藥物的隨機編號。
藥物的隨機編號,即採用隨機的方式來進行藥物編號,要求從藥物編號上無法推斷具體藥物是什麼。
方式
隨機的方式有很多種,在臨床上的應用主要為簡單隨機化、區組隨機化、分層區組隨機化、動態隨機化等。這裏我僅針對臨床較為常用的區組隨機化及分層區組隨機化進行簡單說明。
區組隨機化
顧名思義,一個區組一個區組的進行隨機,一個區組裏治療組和對照組人數均衡;區組長度一般是治療組別個數的2-3倍。比如方案設計中包括兩個治療組,我們採用區組長度為治療組的2倍,則每4個人為一個區組,一個區組裏試驗藥和對照藥人數均衡(即相等)。這樣的話,可以保持試驗藥組和對照藥組隨機人數的任何時刻基本均衡。
分層區組隨機化
由於臨床試驗經常將顯著影響預後(療效)的因素設定為分層因素,(爲了使相同水平的受試者保持治療組間人數均衡。 一般來說分層因素不宜過多,通常最多不超過3個。)每個層採用區組隨機化,就是分層區組隨機化。但如果層數過多,可能會造成組間整體上的不均衡。
假如,某臨床試驗按照性別(男、女)以及年齡分組(>65, <=65)分層,將40例受試者按照1:1的比例隨機到試驗組和對照組。層數為2x2=4個分層,採用分層區組隨機化,區組長度假設為4,那麼極端情況下可能會產生每個層試驗組比對照組都多2個受試者,即總體上試驗組比對照組多4x2=8個人。
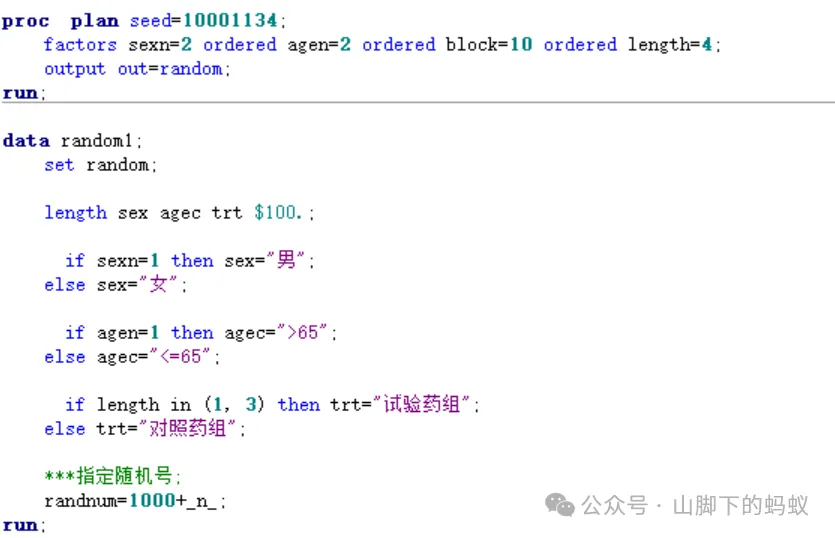
SAS Code
拿上邊分層區組隨機化部分的案例為例,隨機分配表應該如何生成呢?下圖程式供參考。
-
爲了能夠重現,需要指定種子數(也可以選擇隨機生成種子數,但需要注意種子的唯一性) -
由於無法預測未來入組受試者分層的情況,故擴大樣本量,最極端的情況莫過於,40例受試者為同一分層 -
計劃每層人數後,設計區組長度,計算區組個數 -
然後指定隨機分層因素、隨機分組名稱和隨機號(具體指定取值參考方案上的取值)
臨床實施
臨床又是如何實施隨機化呢?從IVRS 互動語音應答系統 (Interactive Voice Response System)到IWRS 互動網路應答系統(Interactive Web Response System)。IVRS現在已經很少用,基本上都是透過IWRS來實現隨機。這個需要相關人員對IWRS進行系統配置、測試然後纔可以上線並匯入正式的盲底。然後臨床相關人員透過觸發隨機相關EDC/IWRS 相關頁面即可以進行篩選成功受試者的隨機分組。
還有另一種隨機的形式,在早期臨床也較為常見,即使用隨機信封。
-
對於開放試驗,列印一套信封,用於隨機(起到分配隱藏的作用)。
為篩選成功準備入組的受試者開啟一個信封,來檢視其分組,然後取對應的藥物給Ta即可。
-
對於雙盲試驗,可以列印一套信封,用於緊急揭盲。
按照隨機表的順序進行藥物編盲(即貼標籤),標籤上顯示藥物號(通常=隨機號或者至少可以和隨機號建立聯絡,比如隨機號後加“-1”)。為篩選成功準備入組的受試者按照方案規定的順序發放隨機號並取對應的藥物編號的藥物給Ta。這裏的隨機信封僅用於緊急揭盲。
盲底
盲底,說直白一點就是,受試者隨機分組的隨機分配表。隨機分配表、相關種子數和區組長度在臨床試驗進行中全程保密。

無論是開放試驗還是雙盲試驗,除非方案明確規定,盲底通常都是在臨床試驗結束後,DBL後進行釋放。
結語
最近有點懈怠了。。。先寫這麼多吧。。。
大家如果有問題,歡迎私信我~
如果有紕漏,也歡迎批評指正~
https://www.cde.org.cn/main/news/viewInfoCommon/d32fdd9744fab914a3d8c360eac14e3c: https://www.cde.org.cn/main/news/viewInfoCommon/d32fdd9744fab914a3d8c360eac14e3c
[2]https://www.cde.org.cn/main/news/viewInfoCommon/402c511b46bfa8c472fd6aad6e164557:
完結
文章來源:5 隨機化如何在臨床試驗中應用? (qq.com)













0則評論