
文章概要:作者山脚下的蚂蚁,详细介绍了SAS编程制作临床试验数据分析图表TFL前的准备工作,给Junior 统计分析程序员提供了详细的思路和方法论。
开篇声明:1. 以下内容非原创,转自微信公众号山脚下的蚂蚁《3 编程制作TFL——从何下手?》,如有侵权,可联系删除
2. 以下观点,仅代表作者个人观点,请带着质疑的态度去阅读。如有问题,欢迎评论区留言或直接联系作者
编程制作TFL——从何下手?
前言
在熟悉了《2 编程预热——编程要求》后,面对一项制作图表 (TFL,Table,Figure,Listing) 的任务,该从何下手呢?这应该是新入职的统计分析程序员比较苦恼的事。这里我不讲代码(code),我主要讲一下思路和方法论。至于该如何下手写 code,我会专门起一个话题来讲。
正文
详细步骤
开展编程工作前,按照SOP一般需要先完成方案、SAP、CRF的培训,且大多形式为自学,所以新人程序员培训后可能依然稀里糊涂,似懂非懂(不用担心,后边遇到问题了,带着问题再次来培训,更有针对性)。面对一个图表任务,该如何下手呢?
第一步,先来理解 Shell 的格式和含义。每个图表都对应一个清晰 Shell (模板)(如果 Shell 画得好)。看到 Shell 后,不要着急下手开始编程。先从格式和含义上进行理解,有任何的不理解,可以带着问题继续第二步和第三步。到最后如果依然有不理解,可以和Shell的作者(项目统计师)进行沟通。
第二步,再来培训一下方案和 SAP。理解试验设计,看 SAP 上的要求,包括分析指标/变量的定义、分析变量的衍生规则、小数点位数的规则等,再找到 TFL 对应部分的内容好好读一遍。
第三步,培训 CRF/aCRF 和 CCI/CCG(数据填写指南), 确定数据收集规则和对应的变量;然后找到对应的 Spec,从原始数据到SDTM数据,再从SDTM数据到ADaM数据,顺藤摸瓜,一步步来确定分析数据和变量。
具体案例
如下表,这是一个简单的三线表(顾名思义,有三条线的表)。
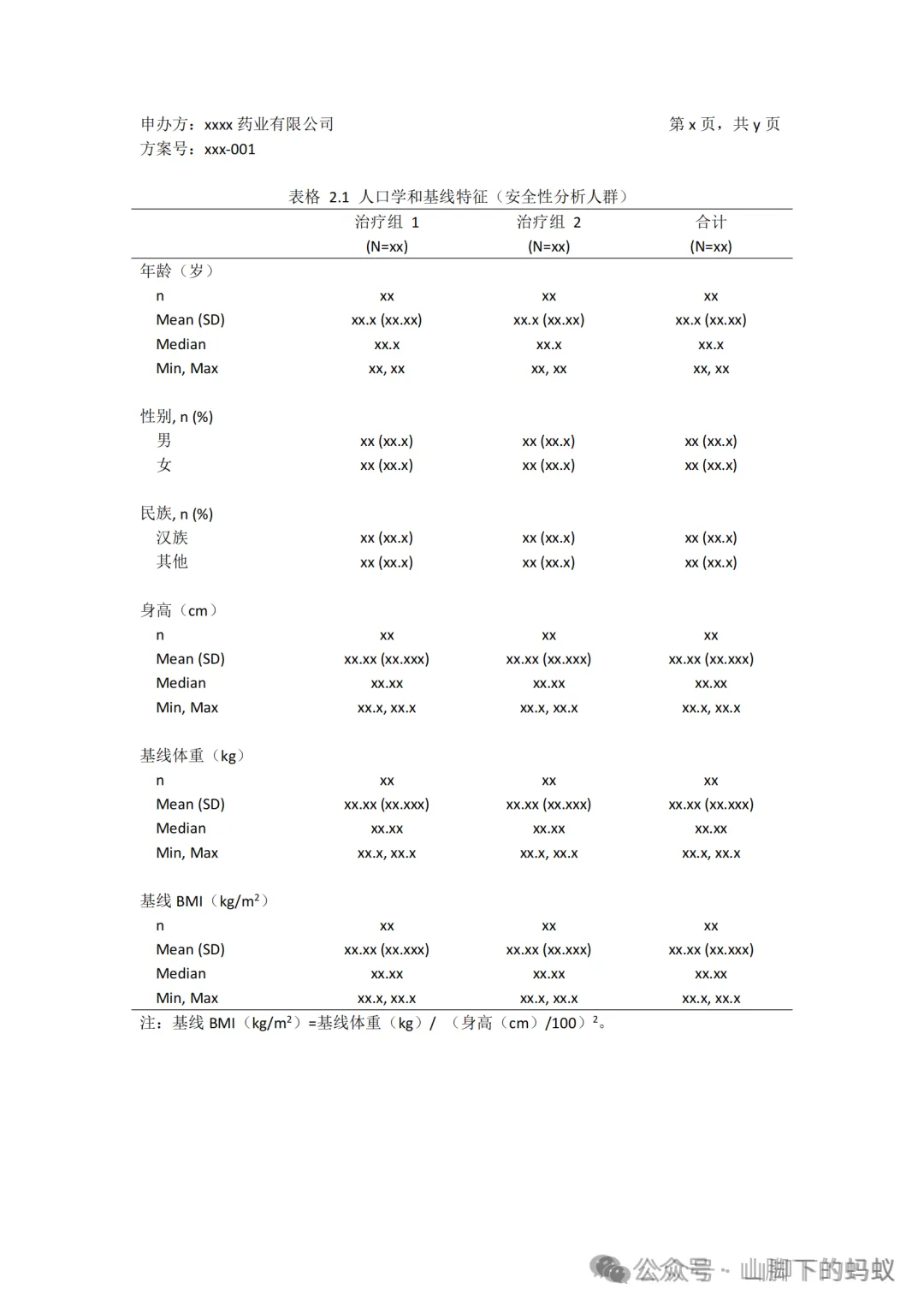
Shell的格式
-
第一条线上面属于标题(title)部分,有效信息仅有“表格2.1 人口学和基线特征(安全性分析人群)”;其他是general的信息(申办方,方案号,页码等),一般编程Lead会设置好,无需过多关注。 -
第一条和第二条线之间属于表头(header),这里为治疗组的信息;第二条和第三条线之间部分是表身(body), 为不同指标汇总了不同统计量; -
第三条线下面为注释(footnote)部分,用来解释说明上文变量或指标的取值规则。这里的上文不仅包括body还可以包括title。
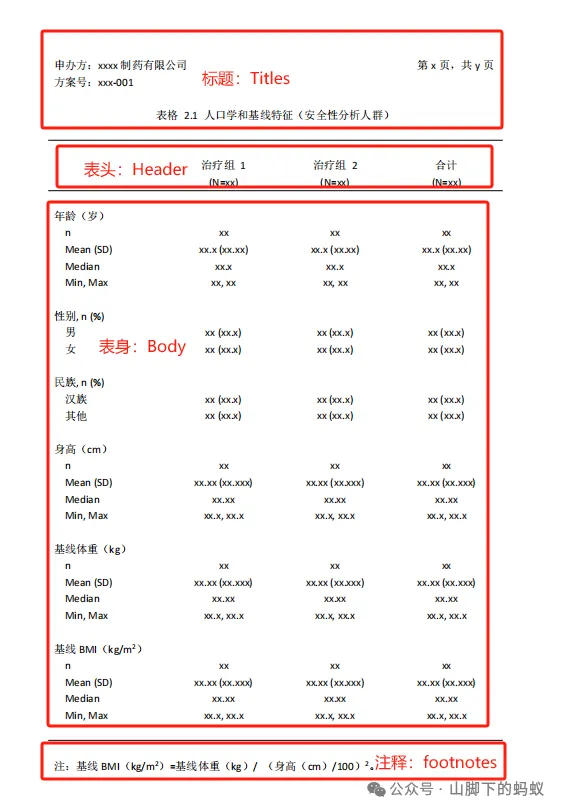
Shell的含义
再来看一下表的含义。首先就是人群(Population)——title中的“(安全性分析人群)”,其次是主题(Topic)——title中的“人口学和基线特征”,最后是表身关注的指标/变量以及统计量。
故上表关注的内容(含义)为,安全性分析人群的人口学和基线特征相关的变量,连续型指标(年龄、身高、基线体重、基线BMI)的统计量,以及分类型指标(性别、民族)的分类计数。
培训SAP
理解了Shell的格式和含义后,接下来该如何下手呢,变量在哪个数据集里?变量名是什么?小数点规则为什么年龄和身高体重等指标不一样?带着这些问题再来看SAP里的描述(比如相关指标的衍生规则、缺失数据填补规则、小数点规则等)。比如,关于小数点在SAP有如下描述:

比如对于身高(cm)的统计量Mean,Median的小数位数应该要保留几位呢?原始数据的小数位数是多少呢?对于衍生数据体重指数(BMI)又该如何保留小数位数呢?请移步到下一步里看结果。
培训CRF以及找数据和变量
第三步,查看aCRF上的对应变量(对于该数据/变量的收集规则,如有不解,可以参看CCI/CCG对应部分的描述),然后找到对应的SDTM Spec,追溯从原始数据到SDTM数据;再查看ADaM Spec,从SDTM数据到ADaM数据,顺藤摸瓜,一步步来确定分析数据和变量。需注意的是,数据管理(DM)和统计都有一个aCRF:DM的aCRF标识的是原始数据的数据集名称以及变量名等信息;统计的aCRF是原始数据标准化后的SDTM数据对应的数据集名称以及变量名(如下图)。
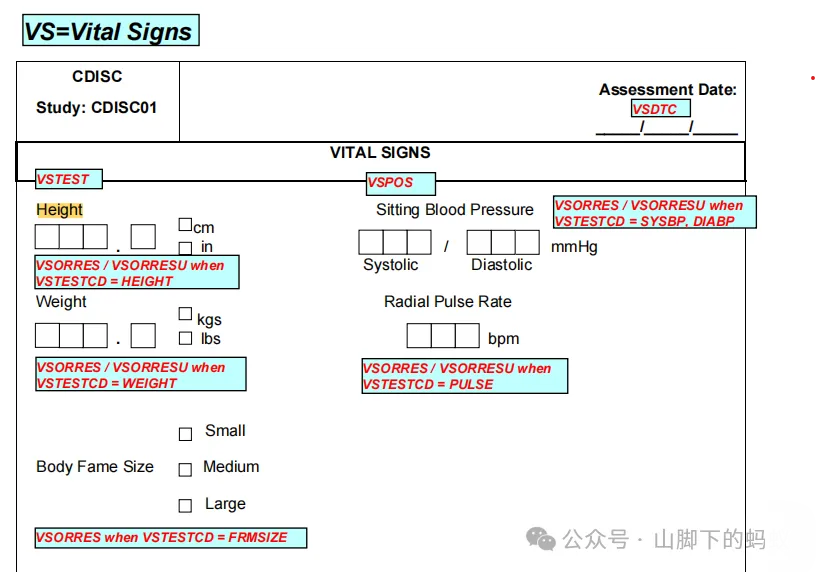
从上图我们可以看到,身高、体重变量被收集在SDTM VS数据集里,身高同体重一样,原始数据都是1位小数;根据案例SAP的描述,BMI的原始数据按照2位小数来做。
这样的话,身高和体重的统计量Mean和Median按照两位小数,SD按照三位小数,Min和Max按照一位小数来展示;BMI的统计量Mean和Median按照三位小数,SD按照四位小数,Min和Max按照两位小数来展示。需要注意的是,此时BMI的小数位数同Shell的位数规则不一致,从而需要和项目统计师进行沟通解决方法。总之,谨记:遇到任何的问题都可以保持和统计师的沟通。但前提一定是调研过,思考后,再来沟通。
另外,需要注意的是Shell中的指标为基线体重以及基线BMI,那么基线是什么含义呢?需要再到SAP中寻求答案,然后再回到ADaM Spec中找相应的数据集以及变量名。此处不再赘述。
结语
虽然无论黑猫白猫,只要抓住老鼠都是好猫。有经验的临床统计分析程序员均知悉上述人口学和基线特征数据通常会包括在ADaM ADSL中(ADSL为受试者水平的数据集,一个受试者一条记录),可能会说,直接到ADSL里找相应的数据/变量即可,不需要按照步骤一二三那么麻烦。这里我想说,我这里讲的是方法论哈,当你不知道或不确定收集在哪个数据的哪个变量的时候,按照上述的步骤,会更加有效和更有收获。
按照上述的步骤做下来,你对试验设计、数据从CRF设计、收集规则、分析方法和结果都会加深理解。个人理解,做项目不在于多,而在于精。希望大家做每个项目都有收获。
如有纰漏,欢迎私信批评指正~
如有不解,也欢迎私信交流~
完结











0条评论