
文章概要:作者山脚下的蚂蚁,介绍了临床试验的SAS编程生成TFL的详细步骤,从setup到详细程序及其逻辑等
开篇声明:以下内容非原创,转自微信公众号山脚下的蚂蚁《4 如何编程?—— 编程案例讲解》,如有侵权,可联系删除
如何编程?—— 编程案例讲解
前言
千呼万唤始出来,终于要来分享如何编程了(交作业啦)。有了前文分享的《3 编程制作TFL——从何下手?》以及《3.1 编程制作TFL——从何下手?(补充篇)》的基础,相信大家对相关的方法论有了基本掌握。是时候引入正题了,那么该如何开展编程呢?
犹记得,之前我刚招聘的一个小朋友,勤奋好学,刚入职时在看一本临床统计程序员相关的编程书籍,(能出书应该是在行业里干了好多年的编程人员。但其程序对初入职场的小朋友确实不友好)。他有一些不解,拿着书来问我,我看了一下,直接(大言不惭地)说不要看了。这本书上的逻辑是一行一行的生成Shell对应的output。
你可能会问,你的程序一定比他好很多吗?我想说,不一定哈,但是至少是简单、逻辑清晰。哈哈,大言不惭(咱这么十多来年的编程经验也不是没点水平)。少啰嗦,进入正题。本次分享依旧以《人口学和基线特征》为案例,数据来自ADaM_IGv1.1_package中ARM-for-Define-XML的ADaM ADSL。
声明:由于用的是外部下载数据,无相关的SAP以及CRF, 且本表比较简单,故这里假设我已经对SAP进行过了良好的培训和理解了。大家在做具体项目的时候一定好好培训和学习SAP以及CRF哈。
正文
0. 编程启动会
编程启动前,Lead programmer会进行Kick off meeting, 来介绍:
-
setup.sas,包括设置路径和相应的library(逻辑库),以及常用的宏程序,format,及要生成的RTF template等 -
template codes of SDTM/ADaM,以及相关的Specifications -
template codes of TLFs -
编程的general要求,比如图表的变量长度统一为200、变量名col0-colx、最后的数据集的命名建议为final等
接下来,我将直接进行正题,进行程序正文的讲解。
1. Shell
根据数据中变量取值,我修改了Shell,如下图。
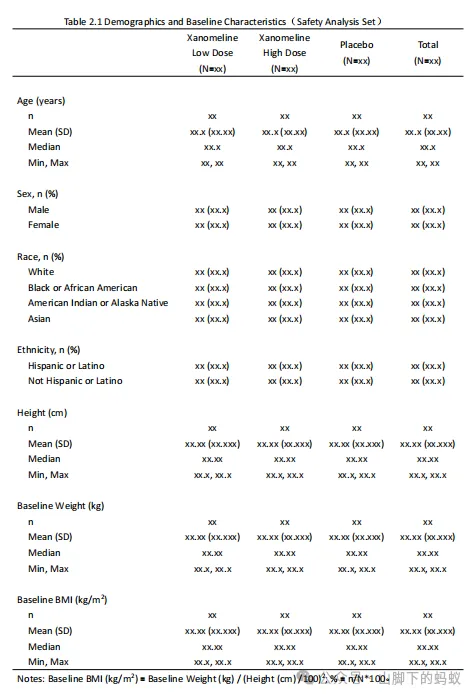
看到Shell后,仔细观察和理解,本表关注的内容(含义)为,安全性分析人群的人口学和基线特征相关的变量,连续型变量(Age, Height, Baseline Weight, Baseline BMI)的统计量,以及分类型变量(Sex, Race, Ethnicity)的分类计数。为了编程准备,我将Shell进行了如下标注(这样是不是逻辑更清晰一些?),然后开始进行编程。
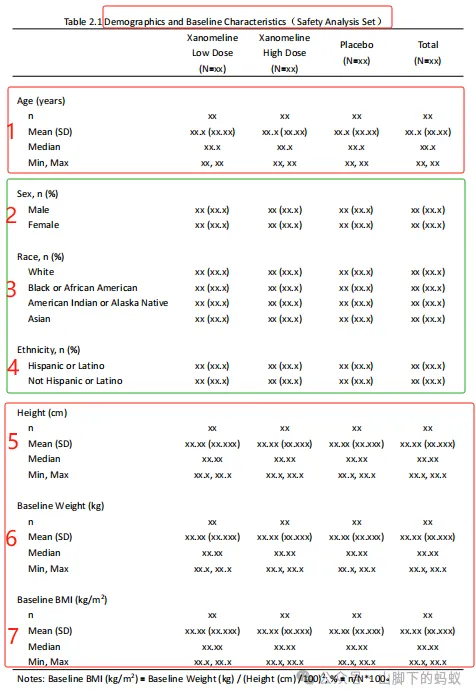
2. Keep 数据和变量
第一步,我们首先找到对应人群的数据,然后keep相应的变量,然后对比Shell和数据:

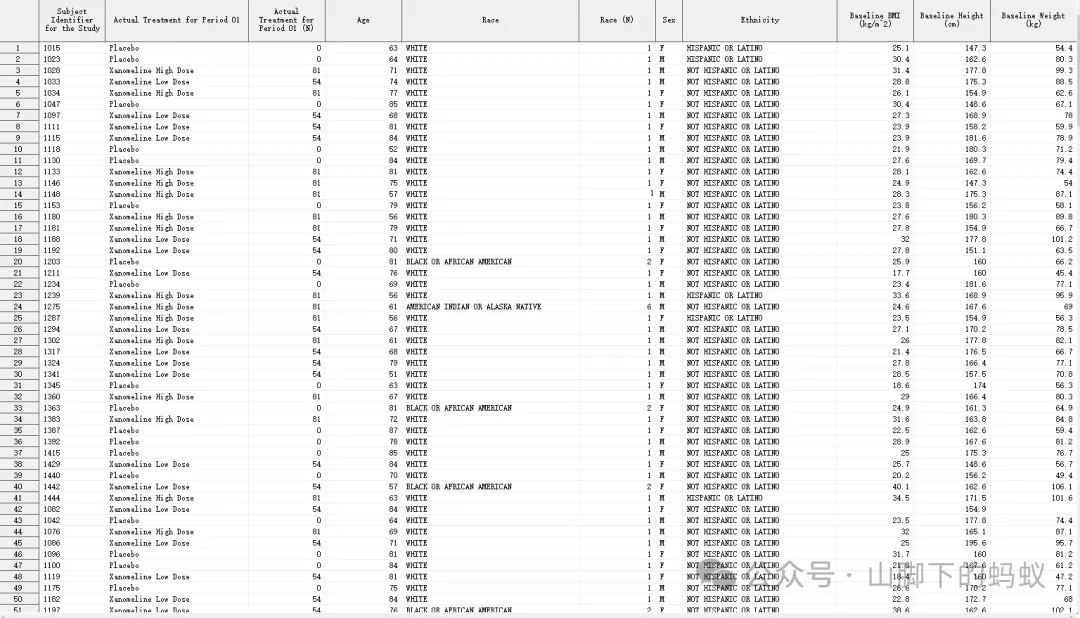
运行后发现,连续型变量的单位和Shell中一致无需转换单位,但分类型变量的取值和Shell中稍有差异:
-
Sex的数据取值为F、M,但Shell中为Male,Female,需要特殊处理(这里我使用format,你也可以采用if语句) -
Race 和 Ethnicity 的数据和Shell中也不一致,但两者字母大写一致 -
数据中无治疗组=“Total”,需要增加相关数据
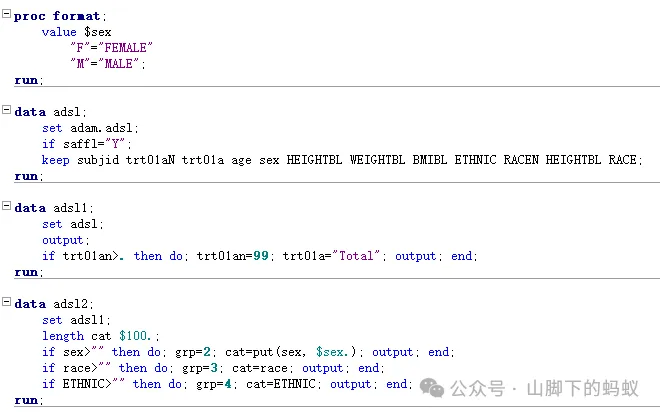
3. 连续型变量
数据处理好了,接下来我们开始进行数据处理,首先是连续型变量的处理,这里我们经由观察Shell(和培训CRF和SAP,假设哈)得知:
-
Min/Max保持和原始数据小数位数一致,Mean/Median的小数位数=原始数据小数位数+1,SD的小数位数=原始数据小数位数+2 -
Age原始数据为整数,Height、Weight、和BMI的原始数据小数位数均为一位(其中BMI为CRF收集的数据,是EDC系统根据Height、Weight自动计算得来,保留了一位小数)。 -
计算过程除了变量和小数位数的不同,无其他差异(故我采用宏程序来实现) -
除了变量的顺序,统计量(n, Mean, SD, Median, Min, Max)的格式以及顺序也需要注意
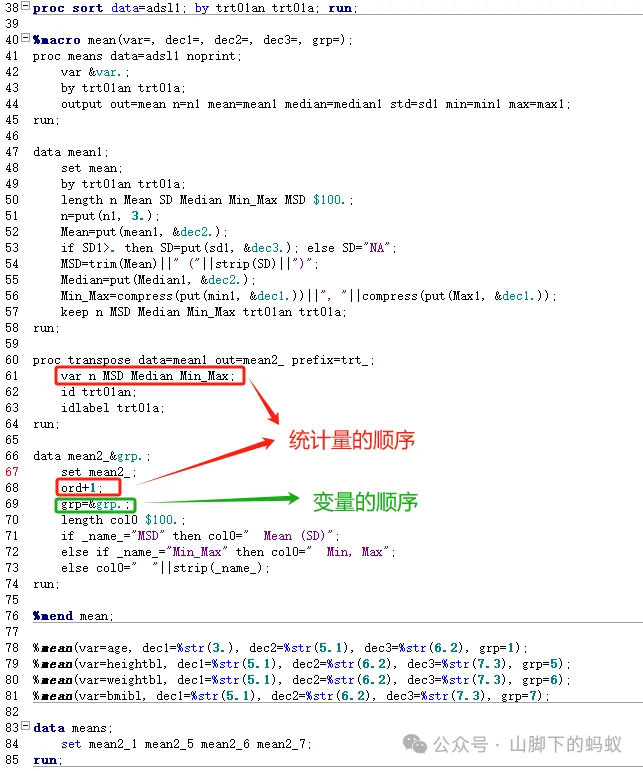
写宏程序的时候,建议初学者先按照一个变量将数据处理好,然后再将变化的部分替换成宏变量。同时需要考虑变量的顺序,以及变量相关统计量的顺序。上述程序利用了transpose 变量(Var n MSD Median Min_Max)放置的顺序决定了统计量的顺序。到此,连续性指标的数据基本处理完毕。

4. 分类型变量
接下来是分类型变量的数据处理:
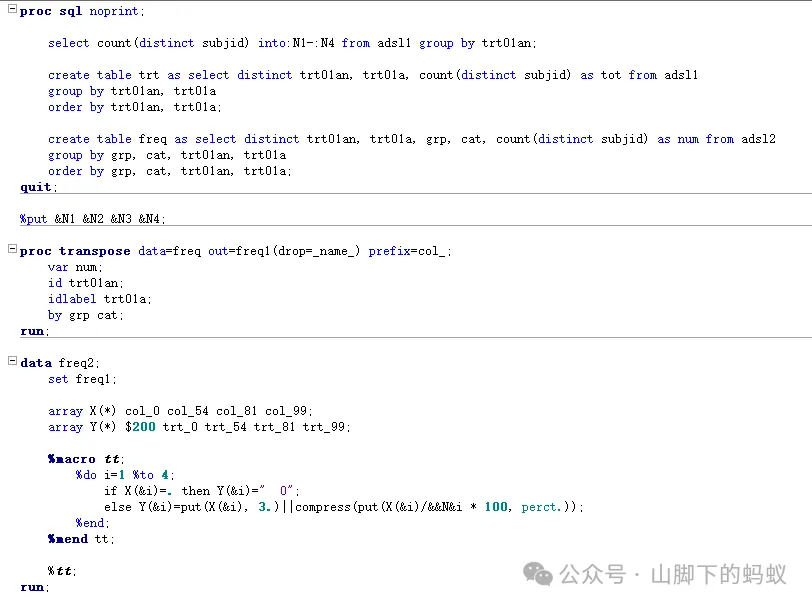
方式1:
-
百分比的分母都是N,选择采用宏变量 -
先transpose 数据,然后分不同治疗组别进行百分比计算 -
优点:0已经处理; -
缺点: N对应的宏变量和治疗组的变量(这里是数值型变量)排序相关,需要注意对应关系
方式2:
-
百分比的计算采用merge 数据集 -
先计算百分比,然后transpose字符型数据,存在缺失值,需后期处理 -
优点:1) N对应的宏变量和治疗组的名字相关,对应关系明确;2)百分比的计算不容易出错。当治疗组组别较多时,尤其推荐这种处理方式。 -
缺点:数值0需要额外处理 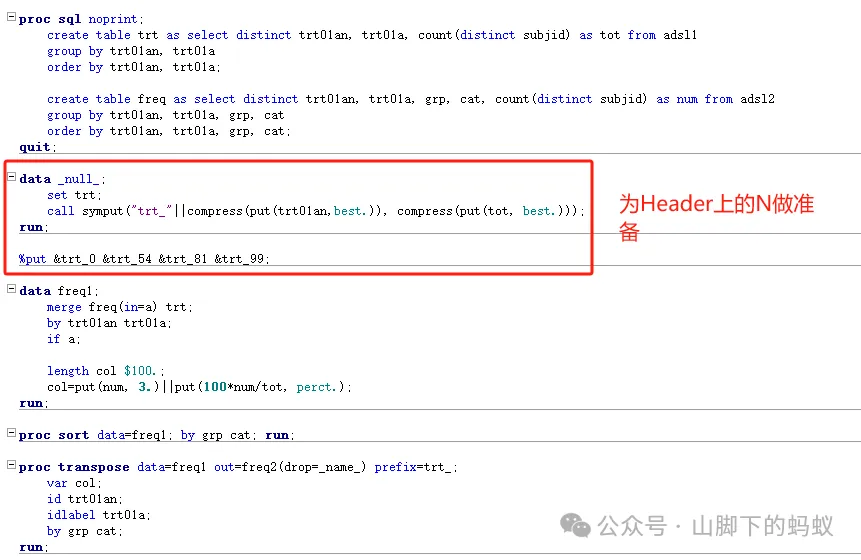
5. Dummy数据集
按照方式2的处理,将连续型处理结果和分类处理结果放到一起,得到数据:

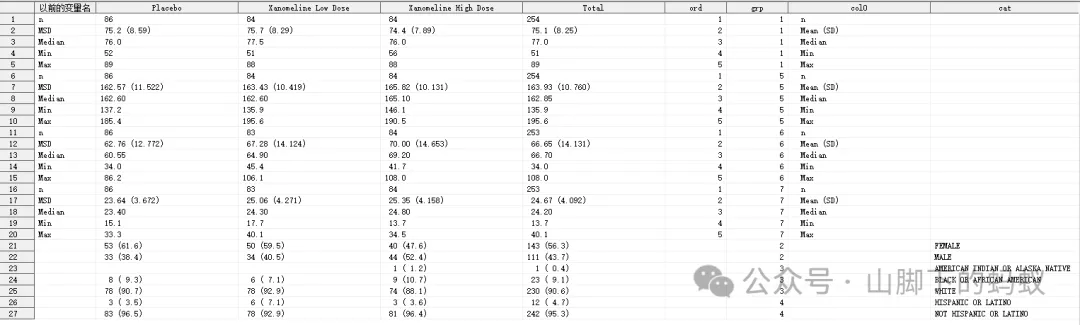 到这里,还剩下1)第一列col0 的显示问题,以及2)分类变量显示为空(结果为0)的处理问题。现在来Dummy col0。
到这里,还剩下1)第一列col0 的显示问题,以及2)分类变量显示为空(结果为0)的处理问题。现在来Dummy col0。
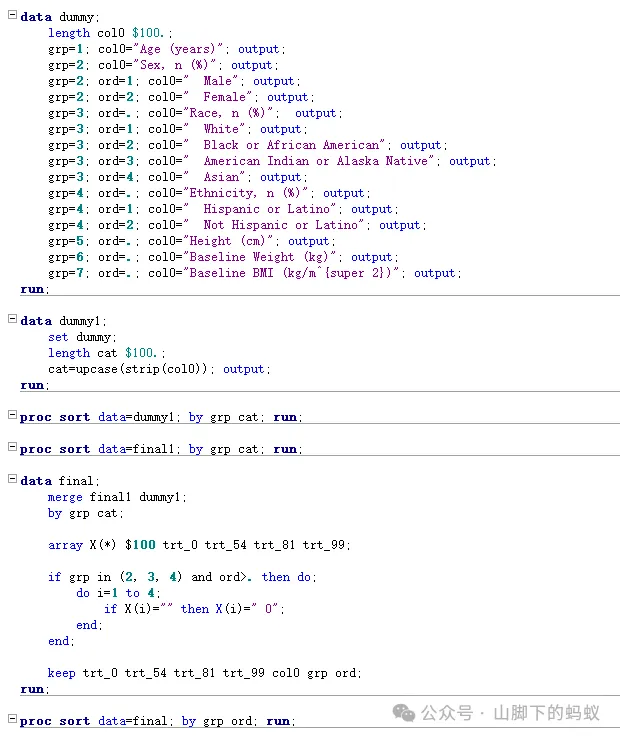
得到最后的final数据:
-
dummy排序变量和col0后,采用变量顺序grp, 和upcase(col0)进行merge然后得到了col0 -
dummy数据merge后得到分类型指标取值为0的行,比如race中的Asian行(分类型变量采用方式1处理的话,也需要处理这种情况)。和分类型指标取值为0的列一起处理掉。 -
按照顺序变量排序。grp代表变量顺序,ord代表连续型变量的统计量或者分类型变量分类的排版顺序。
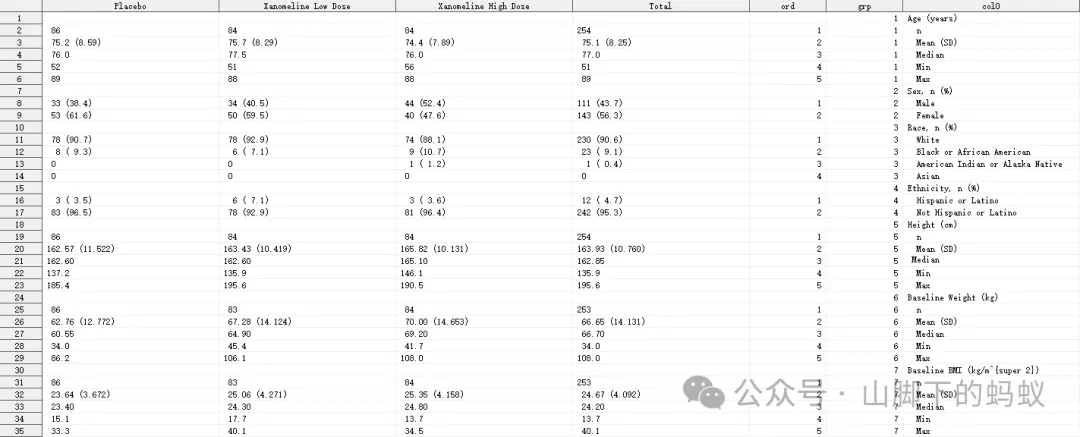
接下来就是report部分,属于TLF template code的一部分,不再展示。整个程序算上header和report,大约200多行codes, 即可生成相应的output。
6. 重要事项
以下是我认为的重要事项(欢迎私信补充哈):
-
编程过程中,每写一段code,即运行查看对应的log是否clean,以及生成的数据集是否符合预期,然后写下一段code -
编程过程中或结束后,想到更好的解决方法,及时修订和改进。改进的是逻辑和编程习惯 -
添加comments备注想法或逻辑,及特殊处理的原因等(哈哈,这点我也没做到位:上述程序较为简单,comments较少);删除大段的、没有用的comments程序 -
如果遇到数据问题或编程问题,及时记录issue log;程序中可增加测试data issue的语句,以便下次运行注意到issue的状态 -
为了和Shell保持一致,dummy data或footnotes尽量从Shell上copy - paste, 减少手动输入 -
output生成后,仔细检查:1)格式:title / body / footnotes等信息和Shell的一致性;2)理解数值:header上的N,body中的数值,看是否有data issue(及时记录和上报)等;3)Page:是否有页码问题或者空白页等; 4)cross check:表内和表间相同/相关数值是否一致等
结语
虽说黑猫白猫抓住老鼠都是好猫,但对于程序员来说,能正确生成图表是最低要求;程序有好的可读性、清晰的逻辑至关重要(好处多多,不再展开赘述哈)。临床程序员是作者,不是读者。希望大家谨记。
每个程序员都有自己的编程习惯,小编希望助你养成好的编程思路/习惯,如果你能从本篇有所收获或启迪,不幸荣幸。
如有问题,欢迎私信我~
如有纰漏,也欢迎私信我沟通~
问题回复
《3.1 编程制作TFL——从何下手?(补充篇)》的遗留了两个问题,我放在本篇最后进行回复。
-
如果标题为“年龄>=65岁受试者的不良事件(安全性分析人群)”,那么N的含义又是什么呢?
参考回复:N的含义为,不同治疗组实际用药的年龄>=65岁受试者中的人数以及合计的用药的年龄>=65岁受试者人数。
-
如果标题为“不良事件(安全性分析人群)” 按照年龄分层(>=65岁, 以及<65岁)分别汇总,那么N的含义又是什么呢?
参考回复:N的含义为不同治疗组实际用药的年龄>=65岁受试者或<65岁受试者人数以及合计的用药的年龄>=65岁受试者或<65岁受试者人数。
完结













0条评论