
文章概要:作者山腳下的螞蟻,介紹了臨床試驗的SAS程式設計生成TFL的詳細步驟,從setup到詳細程式及其邏輯等
開篇宣告:以下內容非原創,轉自微信公眾號山腳下的螞蟻《4 如何程式設計?—— 程式設計案例講解》,如有侵權,可聯絡刪除
如何程式設計?—— 程式設計案例講解
前言
千呼萬喚始出來,終於要來分享如何程式設計了(交作業啦)。有了前文分享的《3 程式設計製作TFL——從何下手?》以及《3.1 程式設計製作TFL——從何下手?(補充篇)》的基礎,相信大家對相關的方法論有了基本掌握。是時候引入正題了,那麼該如何開展程式設計呢?
猶記得,之前我剛招聘的一個小朋友,勤奮好學,剛入職時在看一本臨床統計程式設計師相關的程式設計書籍,(能出書應該是在行業裡幹了好多年的程式設計人員。但其程式對初入職場的小朋友確實不友好)。他有一些不解,拿著書來問我,我看了一下,直接(大言不慚地)說不要看了。這本書上的邏輯是一行一行的生成Shell對應的output。
你可能會問,你的程式一定比他好很多嗎?我想說,不一定哈,但是至少是簡單、邏輯清晰。哈哈,大言不慚(咱這麼十多來年的程式設計經驗也不是沒點水平)。少囉嗦,進入正題。本次分享依舊以《人口學和基線特徵》為案例,資料來自ADaM_IGv1.1_package中ARM-for-Define-XML的ADaM ADSL。
宣告:由於用的是外部下載資料,無相關的SAP以及CRF, 且本表比較簡單,故這裏假設我已經對SAP進行過了良好的培訓和理解了。大家在做具體專案的時候一定好好培訓和學習SAP以及CRF哈。
正文
0. 程式設計啟動會
程式設計啟動前,Lead programmer會進行Kick off meeting, 來介紹:
-
setup.sas,包括設定路徑和相應的library(邏輯庫),以及常用的宏程式,format,及要生成的RTF template等 -
template codes of SDTM/ADaM,以及相關的Specifications -
template codes of TLFs -
程式設計的general要求,比如圖表的變數長度統一為200、變數名col0-colx、最後的資料集的命名建議為final等
接下來,我將直接進行正題,進行程式正文的講解。
1. Shell
根據資料中變數取值,我修改了Shell,如下圖。
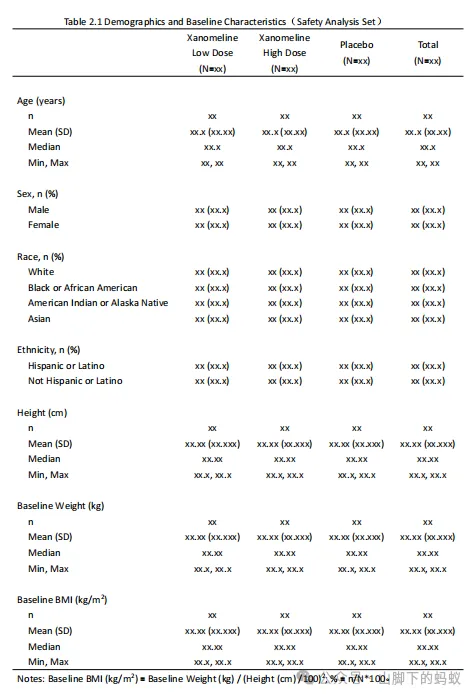
看到Shell後,仔細觀察和理解,本表關注的內容(含義)為,安全性分析人群的人口學和基線特徵相關的變數,連續型變數(Age, Height, Baseline Weight, Baseline BMI)的統計量,以及分型別變數(Sex, Race, Ethnicity)的分類計數。爲了程式設計準備,我將Shell進行了如下標註(這樣是不是邏輯更清晰一些?),然後開始進行程式設計。
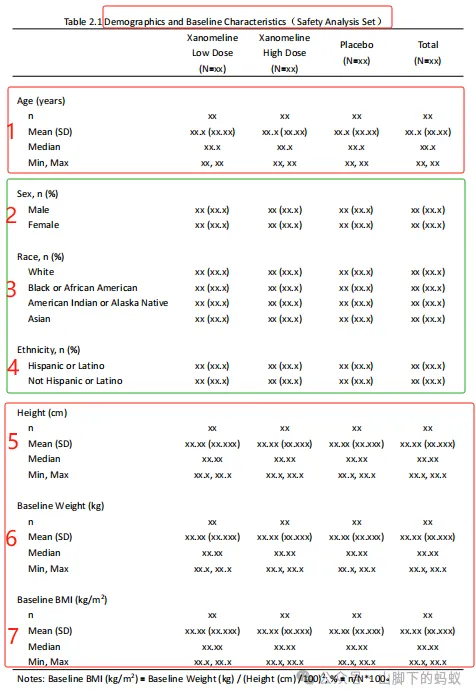
2. Keep 資料和變數
第一步,我們首先找到對應人群的資料,然後keep相應的變數,然後對比Shell和資料:

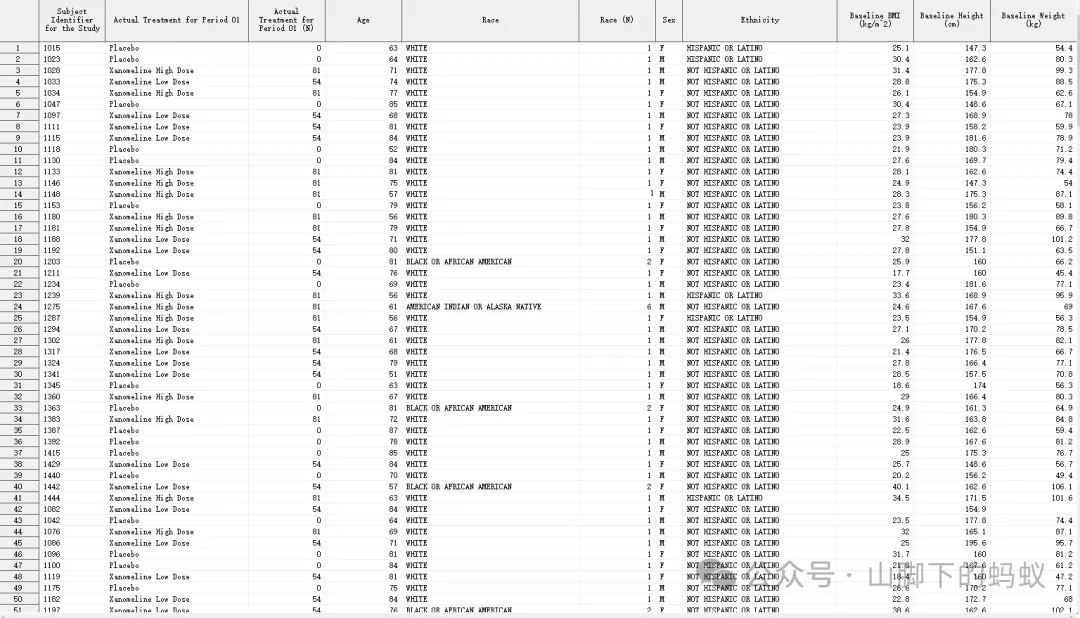
執行後發現,連續型變數的單位和Shell中一致無需轉換單位,但分型別變數的取值和Shell中稍有差異:
-
Sex的資料取值為F、M,但Shell中為Male,Female,需要特殊處理(這裏我使用format,你也可以採用if語句) -
Race 和 Ethnicity 的資料和Shell中也不一致,但兩者字母大寫一致 -
資料中無治療組=“Total”,需要增加相關資料
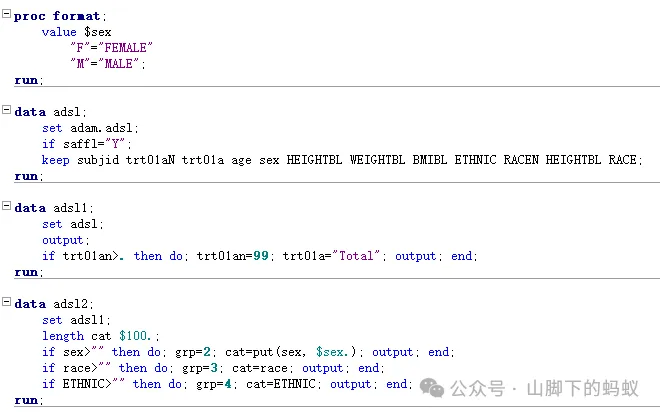
3. 連續型變數
數據處理好了,接下來我們開始進行數據處理,首先是連續型變數的處理,這裏我們經由觀察Shell(和培訓CRF和SAP,假設哈)得知:
-
Min/Max保持和原始資料小數位數一致,Mean/Median的小數位數=原始資料小數位數+1,SD的小數位數=原始資料小數位數+2 -
Age原始資料為整數,Height、Weight、和BMI的原始資料小數位數均為一位(其中BMI為CRF收集的資料,是EDC系統根據Height、Weight自動計算得來,保留了一位小數)。 -
計算過程除了變數和小數位數的不同,無其他差異(故我採用宏程式來實現) -
除了變數的順序,統計量(n, Mean, SD, Median, Min, Max)的格式以及順序也需要注意
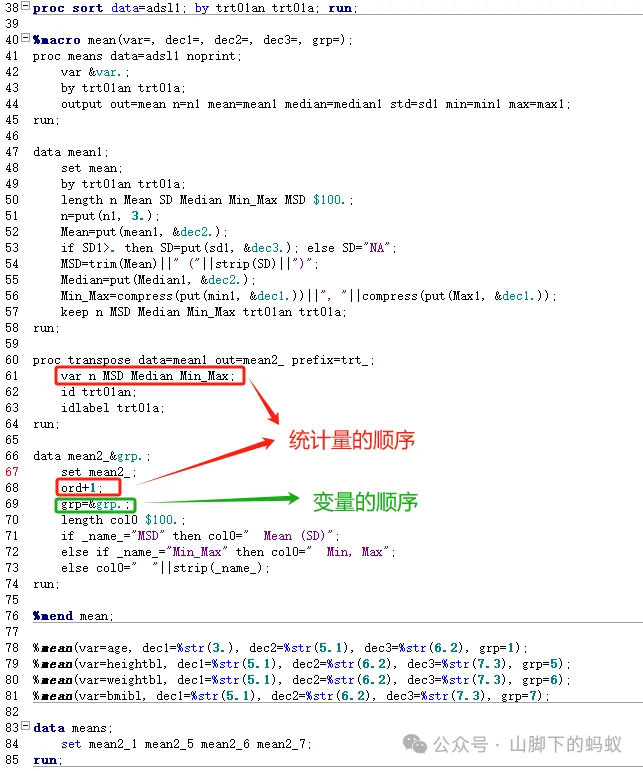
寫宏程式的時候,建議初學者先按照一個變數將數據處理好,然後再將變化的部分替換成宏變數。同時需要考慮變數的順序,以及變數相關統計量的順序。上述程式利用了transpose 變數(Var n MSD Median Min_Max)放置的順序決定了統計量的順序。到此,連續性指標的資料基本處理完畢。

4. 分型別變數
接下來是分型別變數的數據處理:
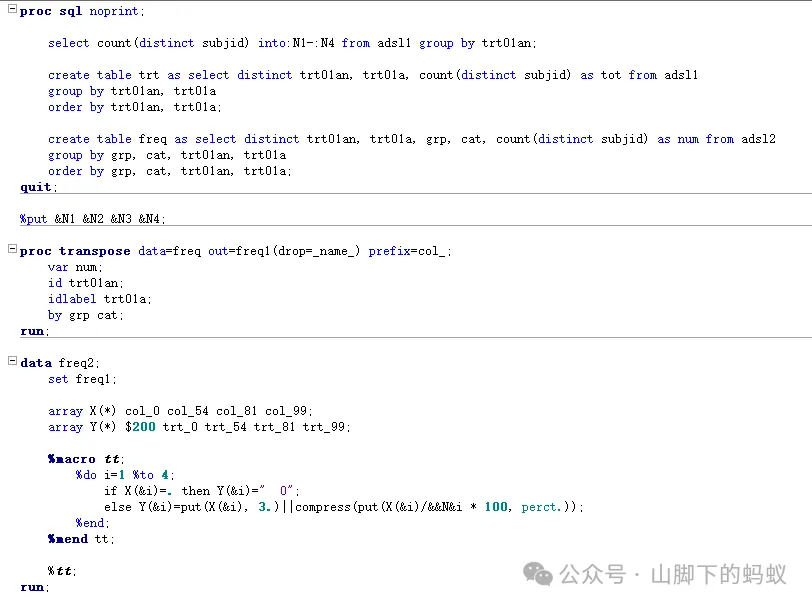
方式1:
-
百分比的分母都是N,選擇採用宏變數 -
先transpose 資料,然後分不同治療組別進行百分比計算 -
優點:0已經處理; -
缺點: N對應的宏變數和治療組的變數(這裏是數值型變數)排序相關,需要注意對應關係
方式2:
-
百分比的計算採用merge 資料集 -
先計算百分比,然後transpose字元型資料,存在缺失值,需後期處理 -
優點:1) N對應的宏變數和治療組的名字相關,對應關係明確;2)百分比的計算不容易出錯。當治療組組別較多時,尤其推薦這種處理方式。 -
缺點:數值0需要額外處理 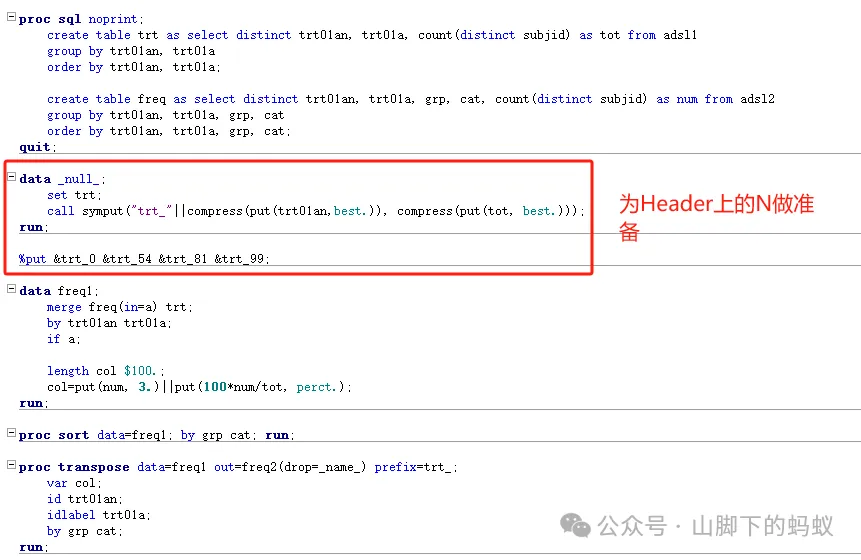
5. Dummy資料集
按照方式2的處理,將連續型處理結果和分類處理結果放到一起,得到資料:

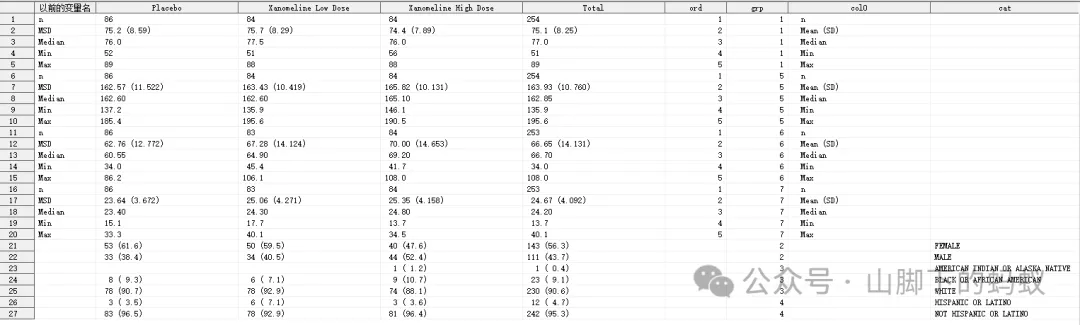 到這裏,還剩下1)第一列col0 的顯示問題,以及2)分類變數顯示為空(結果為0)的處理問題。現在來Dummy col0。
到這裏,還剩下1)第一列col0 的顯示問題,以及2)分類變數顯示為空(結果為0)的處理問題。現在來Dummy col0。
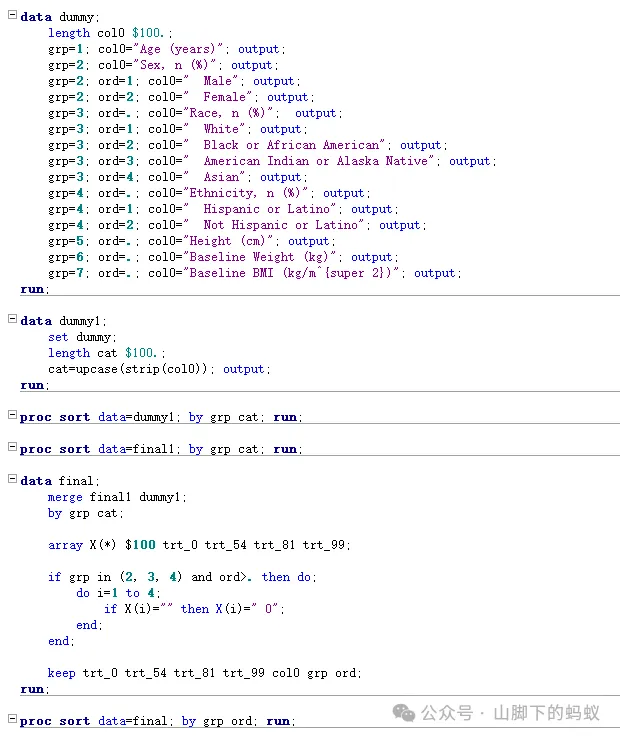
得到最後的final資料:
-
dummy排序變數和col0後,採用變數順序grp, 和upcase(col0)進行merge然後得到了col0 -
dummy資料merge後得到分型別指標取值為0的行,比如race中的Asian行(分型別變數採用方式1處理的話,也需要處理這種情況)。和分型別指標取值為0的列一起處理掉。 -
按照順序變數排序。grp代表變數順序,ord代表連續型變數的統計量或者分型別變數分類的排版順序。
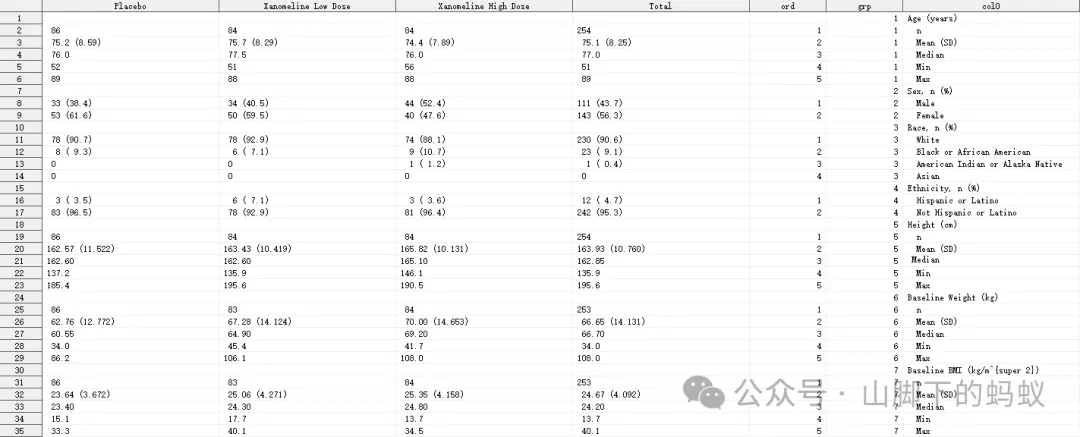
接下來就是report部分,屬於TLF template code的一部分,不再展示。整個程式算上header和report,大約200多行codes, 即可生成相應的output。
6. 重要事項
以下是我認為的重要事項(歡迎私信補充哈):
-
程式設計過程中,每寫一段code,即執行檢視對應的log是否clean,以及生成的資料集是否符合預期,然後寫下一段code -
程式設計過程中或結束後,想到更好的解決方法,及時修訂和改進。改進的是邏輯和程式設計習慣 -
新增comments備註想法或邏輯,及特殊處理的原因等(哈哈,這點我也沒做到位:上述程式較為簡單,comments較少);刪除大段的、沒有用的comments程式 -
如果遇到資料問題或程式設計問題,及時記錄issue log;程式中可增加測試data issue的語句,以便下次執行注意到issue的狀態 -
爲了和Shell保持一致,dummy data或footnotes儘量從Shell上copy - paste, 減少手動輸入 -
output生成後,仔細檢查:1)格式:title / body / footnotes等資訊和Shell的一致性;2)理解數值:header上的N,body中的數值,看是否有data issue(及時記錄和上報)等;3)Page:是否有頁碼問題或者空白頁等; 4)cross check:表內和表間相同/相關數值是否一致等
結語
雖說黑貓白貓抓住老鼠都是好貓,但對於程式設計師來說,能正確生成圖表是最低要求;程式有好的可讀性、清晰的邏輯至關重要(好處多多,不再展開贅述哈)。臨床程式設計師是作者,不是讀者。希望大家謹記。
每個程式設計師都有自己的程式設計習慣,小編希望助你養成好的程式設計思路/習慣,如果你能從本篇有所收穫或啟迪,不幸榮幸。
如有問題,歡迎私信我~
如有紕漏,也歡迎私信我溝通~
問題回覆
《3.1 程式設計製作TFL——從何下手?(補充篇)》的遺留了兩個問題,我放在本篇最後進行回覆。
-
如果標題為“年齡>=65歲受試者的不良事件(安全性分析人群)”,那麼N的含義又是什麼呢?
參考回覆:N的含義為,不同治療組實際用藥的年齡>=65歲受試者中的人數以及合計的用藥的年齡>=65歲受試者人數。
-
如果標題為“不良事件(安全性分析人群)” 按照年齡分層(>=65歲, 以及<65歲)分別彙總,那麼N的含義又是什麼呢?
參考回覆:N的含義為不同治療組實際用藥的年齡>=65歲受試者或<65歲受試者人數以及合計的用藥的年齡>=65歲受試者或<65歲受試者人數。
完結











0則評論